
Technické detaily
Tato stránka obsahuje technické detaily systému TermIt. Popisuje jeho architekturu, knihovny, které jsme pro něj vyvinuli, a datový model.
Technologie a architektura
Technicky je TermIt systém skládající se z několika služeb, z nichž jednou je stejnojmenná Webová aplikace. TermIt jako aplikace je rozdělen do dvou sub-projektů: jeden reprezentuje serverovou část, druhý klientskou část. Architektura systému je ukázána v následujícím diagramu.
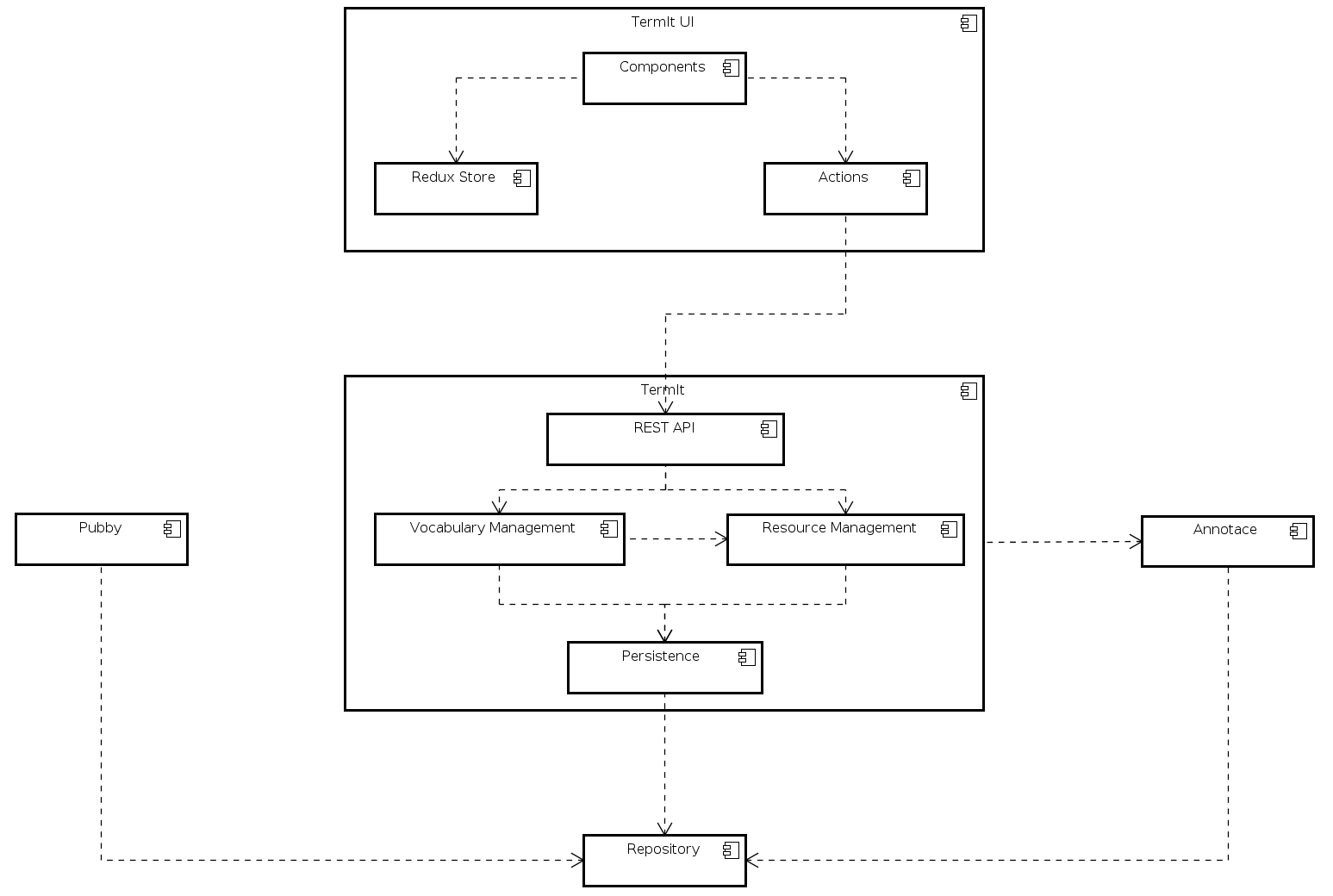
Pozn.: Diagram obsahuje samostatnou službu pro autentizaci a správu uživatelů. TermIt lze také nasadit v konfiguraci, kdy správa uživatelů a přihlašování řeší aplikace TermIt interně.
Serverová část systému TermIt
Serverová část systému je napsána v jazyce Java (17 nebo novější). Jedná se o Java aplikaci založenou na Spring Boot s REST API podporujícícm JSON a JSON-LD. TermIt běží nad triple storem, kam ukládá všechna data. Systém využívá úložiště GraphDB pro jeho vysoký výkon a podporu inferenčních pravidel.
Detailní popis konfigurace a vývoje serverové části TermItu je k nahlédnutí v tomto GitHub repositáři.
Klientská část systému TermIt
Klientská část systému je napsaná v TypeScriptu a používá React framework. Ten byl vybrán pro svou jednoduchost a rozsáhlý ekosystém knihoven.
Zdrojový kód klientské části je v tomto GitHub repositáři, který obsahuje i základní vývojářskou dokumentaci.
Annotace
Jednou z nejdůležitějších funkcí systému TermIt je jeho schopnost analyzovat obsah dokumentů pro vyhledávání výskytu existujících pojmů a navrhování nových pojmů podle jejich významu v textu. Textovou analýzu zajišťuje samostatně vyvinutá open-source knihovna Annotace, kterou můžete najít v jejím GitHub repozitáři.
Validační služba
TermIt podporuje kontrolu kvality pojmů s pomocí SHACL pravidel. Validaci poskytuje samostatná validační služba.
Zajímavé knihovny
TermIt používá několik knihoven vyvinutých pro účely sémantického webu a sémantických dat, které by mohly zajímat i další vývojáře v této obasti. Následující seznam obsahuje jejich shrnutí, včetně základního popisu a odkazu na další zdroje.
JOPA
JOPA (Java OWL Persistence API) je knihovna pro perzistenci sémantických dat. Umožuje práci s doménovým modelem založeným na Java třídách, který je mapován na RDF data v triple storu. Podobně jako JPA knihovna podporuje transakce, mapování výsledků dotazů a cachování za účelem co nejhladšího vývoje informačního systému založeného na principech sémantického webu.
Pro integraci JOPA s deklarativní správou transakcí Springu (@Transactional), která je použita v systému TermIt, byla
vyvinuta tato knihovna.
JB4JSON-LD
JB4JSON-LD (Java Binding for JSON-LD) je knihovna pro snadné mapování POJO na JSON-LD a naopak. Integruje se s Jacksonem, takže použití v aplikaci je otázkou pouze několika řádek kódu.
Datový model
Slovníky modelované v systému TermIt jsou kompatibilní se standardem SKOS. Kompletní datovým model navíc používá další ontologie – ontologii pro Popis dat a TermIt ontologii. Oba modely byly vytvořeny Skupinou znalostních a softwarových systémů (KBSS).
Ontologie popis dat
Základní ontologie použitá k popisu (libolovných) dat se jmenuje Popis dat a její dokumentaci spolu s verzí v různých serializacích RDF najdete na této stránce. Ontologie je založena na Unified Foundational Ontology (UFO) a je určena k popisu libovolných datových zdrojů, např. databází, dat v různých souborových formátech, souborů atd.
Následující sekce popisují základní třídy definované v datovém modelu.
Slovník
Slovník reprezentuje ontologii, která se skládá z glosáře a modelu.
Glosář
Glosář odpovídá SKOS ConceptScheme a reprezentuje seznam všech pojmů ve slovníku.
Model
Model propojuje pojmy definované v glosáři za pomoci ontologických vztahů, především pocházejících z ontologie UFO.
Term
Term odpovídá SKOS Concept a představuje libovolný pojem ve slovníku.
Zdroj
Zdroj představuje původ dat, která jsou modelována, například databáze, soubor atd.
Atribut
Atribut je speciální případem termu, který představuje vlastnost závislou na předmětu popsaném ve zdroji (např. sloupec v databázové tabulce, vlastnost popsaná v dokumentu atd.).
Ontologie TermIt
Ontologie TermIt vznikla během vývoje systému TermIt. Dědí od obecné ontologie Popis dat a rozšiřuje ji o koncepty používané specificky v aplikacích typu TermIt.
Ontologie TermIt obsahuje například pojmy popisující anotaci textů, výskyty pojmů ve zdrojích a správu uživatelů.
Aktuální verze ontologie TermIt je součástí zdrojového kódu TermItu a je dostupná z repozitáře na GitHubu.